Recientemente Ruth Kitchin Tillman, bibliotecaria experta en el trabajo con metadatos, publicó en su blog una entrada muy interesante en la que realizaba una breve introducción al lenguaje de consulta SQL pensada para bibliotecarios. Como me pareció una idea muy buena, me puse en contacto con ella para ver si me permitía traducir su post y adaptarlo a la realidad española. Algo a lo que ella ha accedido de manera muy amable.
En un principio entendía que a mis alumnos les vendría muy bien una introducción de este tipo a modo de refresco de lo que, se supone, saben. Como soy consciente de que la mayoría de ellos está peleado con el inglés, he optado por la adaptación. Es decir, no traduciré de manera literal el texto de Ruth, sino que lo adaptaré a nuestras necesidades. Entiendo que esto también le vendrá bien a aquellos que no sean alumnos míos.
La verdad es que SQL es un lenguaje de consulta bastante sencillo de aprender, pero no por eso deja de ser menos potente. En realidad permite realizar todas las operaciones que se nos ocurran sobre una o varias bases de datos. Evidentemente, el sentido de esta entrada no es la de profundizar en este lenguaje, ya que serían necesarias muchas entradas en este blog. Además, partiré del hecho de que la mayoría de mis lectores son expertos en búsquedas en bases de datos, tal y como se le presupone a un bibliotecario. No obstante, al igual que Ruth, recomiendo la lectura del libro de Michael J. Hernandez, Database Design for Mere Mortals. Para español, siempre me vino bien el libro de Alan Beaulieu titulado Aprende SQL, de la editoral O’Reilly.
Conocer el lenguaje de consulta SQL es fundamental para cualquier bibliotecario (y, por extensión, archiveros, claro). En el momento en el que estamos trabajando con bases de datos, conocer cómo podemos manipular fácilmente gran cantidad de registros para modificarlos, buscar, editarlos… es fundamental. Además, cualquier profesional de la información que se mueva dentro de un entorno web, o que esté relacionado con la arquitectura de la información web, al igual que le sucede a mis alumnos de la asignatura “Tecnologías web para servicios de información”, cuantos más conocimientos tenga de cómo se organiza la información en las bases de datos y de cómo gestionar la información desde el back-end del sistema, mejor.
En el caso de la entrada de Ruth, ella nos cuenta que, al ser su área de trabajo la gestión de metadatos, emplea SQL para realizar consultas con el fin de extraer los metadatos de sus bases de datos, introducirlos en hojas de cálculo, enriquecerlos y, a continuación y por medio de consultas de actualización, mejorar los registros del sistema.
Preliminares: lo que debes saber.
SQL tiene dialectos, que dependen de la instalación con la que estés trabajando. SQL es un lenguaje genérico, pero puede presentar variaciones dependiendo del software que se esté empleando. En esta entrada vamos a hablar de bases de datos MySQL, pero también se puede usar PostgreSQL o SQL Server. Cada una de ellas usa un dialecto diferente de SQL. En realidad hay pocas diferencias desde el punto de vista del lenguaje y del software, pero no merece la pena complicarse demasiado con este tema.
¿Por qué comillas abiertas? ¿Por qué solo en ocasiones? Es posible que, alguna vez, veas sentencias como esta: SELECT `comment_author` FROM `wp_comments`. En MySQL las comillas abiertas se emplean para indicar que una frase es un tipo de identificador: el nombre de una base de datos, el de una tabla o, incluso, el de un campo. De esa manera es posible emplear palabras como `from` como si fueran un nombre, sin causar errores de sintaxis. En esta entrada las emplearemos para indicar que estamos hablando de una base de datos/tabla/campo, pero no se usarán en los códigos que pongamos de ejemplo, que estarán hechos en SQL a secas. Otra cuestión con respecto a las comillas en SQL. Puede resultar algo desconcertante, pero se pueden emplear 3 tipos. Las comillas dobles (“) se emplean para delimitar identificadores (nombre de una tabla, de un campo…). Las comillas simples (‘) se usan para cadenas de caracteres. Por último las que en inglés se denominan backticks y que en español se han traducido por comillas abiertas o, en ocasiones, comillas de ejecución.
¿Por qué tenemos que saber SQL?
La primera respuesta es bastante clara: porque una parte importante de nuestro trabajo se centra en buscar información. Una vez que tenemos claro lo que queremos, el siguiente paso es ir a la interfaz correspondiente y rellenar los campos que necesitamos. En muchas ocasiones esas consultas que realizamos no difieren demasiado de lo que se debería hacer en SQL. De hecho, cuando vas a una base de datos e introduces en el campo “título del artículo” los datos correspondientes al título del artículo que estás buscando has seguido, en esencia, un proceso similar al que se realizaría en SQL. Otro ejemplo lo tienes en los informes que le solicitas a tu programa de automatización de bibliotecas.
Podríamos decir que ya sabes lo que quieres, cómo y dónde buscarlo. Lo que ahora necesitas es conocer el lenguaje en el que expresar todo eso. Y a ahí es donde vamos ahora.
Conoce tu base de datos
Asumiendo que tienes la posibilidad de realizar búsquedas en una base de datos, es evidente que necesitas saber sobre qué campos estás realizando esa consulta. Por ejemplo, imagina buscar en JSTOR. Sabes que puedes hacer consultas tanto en la interfaz básica como en la avanzada. En ambas opciones tienes la posibilidad de buscar en los campos (autor, título, materia…) que te convengan en función de tus necesidades. E, incluso, si no estás familiarizado con esta base de datos, puedes seguir consultándola de manera sencilla porque todas las opciones de búsqueda se visualizan en una única pantalla. En SQL sucede algo parecido aunque, para ser sinceros, la organización de los campos y de la información no siempre es tan evidente.
Todas las bases de datos contienen múltiples tablas, organizadas en función del tipo de dato que almacenarán, como `omeka_options`o `accessions`. Las tablas contienen campos, de manera muy similar a como sucede en las columnas de la hoja de cálculo Excel. En, por ejemplo, una tabla sencilla nos podemos encontrar un campo para el título del libro, otro para la fecha de publicación, para el índice…
Existen dos formas de averiguar qué tablas tiene una base de datos y qué campos contiene, lo que te ayudará a formarte una idea de qué información guarda cada tabla.
Empleo de una interface.
La mayoría de interfaces permite mostrar la información de las tablas de manera visual, muy amigable para el usuario. Uno de las herramientas más empleadas en este sentido es phpMyAdmin. Se trata de un software gratuito que se encuentra integrado en la mayoría de soluciones XAMPP y servicios de hosting, aunque también se puede instalar de manera individual.
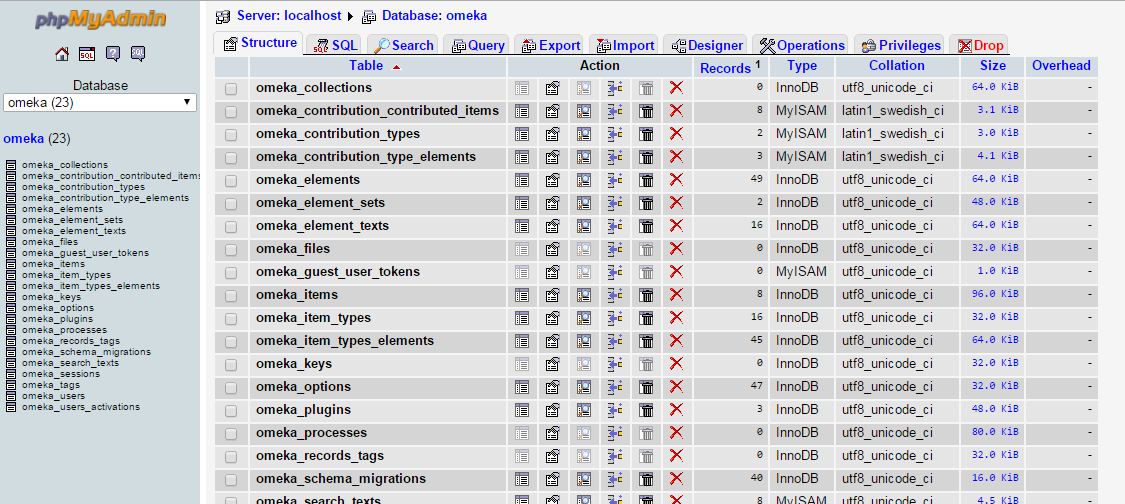 Como podemos ver en la imagen, si selecciono una base de datos en la parte de la derecha aparecerán las tablas y sus características. Si selecciono una tabla se pueden ver los campos, así como los registros de cada tabla. Eso me da una idea de lo que tengo por delante.
Como podemos ver en la imagen, si selecciono una base de datos en la parte de la derecha aparecerán las tablas y sus características. Si selecciono una tabla se pueden ver los campos, así como los registros de cada tabla. Eso me da una idea de lo que tengo por delante.
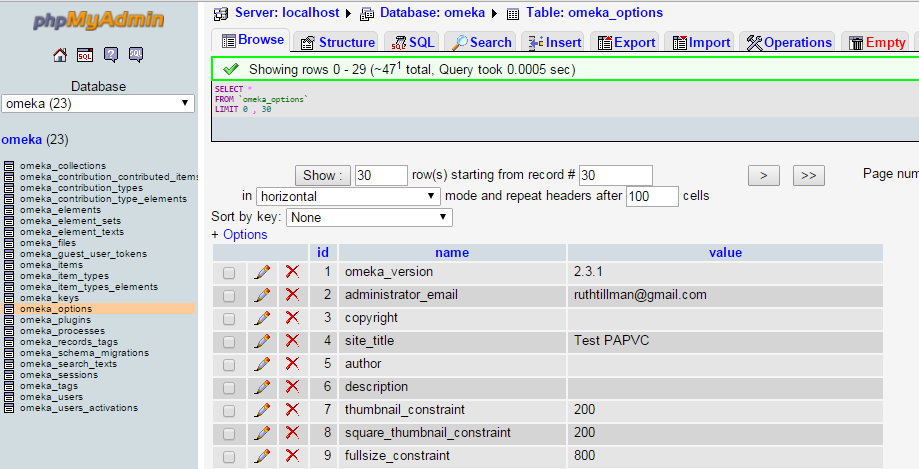 Si te fijas, en la parte superior de la pantalla aparece una sentencia SQL que es, en realidad, la que se ha empleado para generar la página que estoy visualizando.
Si te fijas, en la parte superior de la pantalla aparece una sentencia SQL que es, en realidad, la que se ha empleado para generar la página que estoy visualizando.

Consultado información detallada de la tabla.
Es posible obtener información más detallada si ejecutamos una consulta en MySQL. Si, por ejemplo, escribo:
SHOW TABLES; |
El cliente responderá con una lista de todas las tablas de la base de datos, de tal forma que ya sabremos sus nombres.
A continuación necesitamos saber, además del nombre de los campos, algo de información sobre el tipo de dato que contienes. Para eso, y empleando el nombre de la tabla, ejecutamos la orden:
DESCRIBE omeka_options; |
Y obtenemos
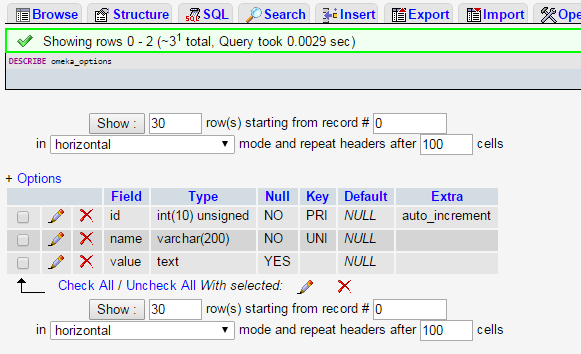 La primera columna muestra el nombre del campo, la segunda nos dice el tipo de dato que acepta dicho campo. Cuando se está empezado, con conocer estos dos datos (además de la llave) es suficiente. La tercera columna nos dice si ese campo puede estar vacío o no. La cuarta muestra el tipo de llave con la que se trabaja en cada campo. Hablar de esto supondría una entrada nueva, así que no entraremos demasiado a profundizar en este tema. De hecho, para hacer consultas sencillas no necesitas conocer el tipo de llave de cada campo. La quinta columna indica si existe algún valor predeterminado (como verdadero o falso). En nuestro ejemplo, ningún campo tiene valores de este tipo. La última columna indica que el campo id se alimenta automáticamente, con un número integral, de manera incremental.
La primera columna muestra el nombre del campo, la segunda nos dice el tipo de dato que acepta dicho campo. Cuando se está empezado, con conocer estos dos datos (además de la llave) es suficiente. La tercera columna nos dice si ese campo puede estar vacío o no. La cuarta muestra el tipo de llave con la que se trabaja en cada campo. Hablar de esto supondría una entrada nueva, así que no entraremos demasiado a profundizar en este tema. De hecho, para hacer consultas sencillas no necesitas conocer el tipo de llave de cada campo. La quinta columna indica si existe algún valor predeterminado (como verdadero o falso). En nuestro ejemplo, ningún campo tiene valores de este tipo. La última columna indica que el campo id se alimenta automáticamente, con un número integral, de manera incremental.
Consulta de ejemplo
Cuando antes se comentó la existencia de phpMyAdmin se empleó una búsqueda determinada. La manera más sencilla de obtener algo parecido es ejecutar lo siguiente:
SELECT * FROM TABLE_NAME LIMIT 25 |
El resultado de esta búsqueda en un listado con las 25 primeras entradas de la tabla. Más adelante explicaré cada uno de los elementos que componen esta consulta. Con esa búsqueda puedo saber, por ejemplo, que existe un campo que se denomina `location` que usa el valor “nuevo” cuando se adquiere un libro nuevo, o el valor “sl2” cuando el libro está en la segunda estantería, etc. Esta información me permitirá construir búsquedas más adelante.
Escribir, escribir, escribir
Si estás haciendo una búsqueda es, posiblemente, porque necesites algo. A lo mejor es información. Quizá quieras hacer una hoja de cálculo con algunos datos. O puede que necesites una lista de títulos de documentos con una característica especial. O un artículo del que sólo conoces el DOI.
A pesar de llevar muchos años usando SQL, aún siento la necesidad de anotar, de ayudarme con un lapiz y un papel en mis consultas. Especialmente si son complicadas. Emplea lo que has escrito en tus anotaciones para construir las ecuaciones de búsqueda. Esas notas te ayudarán a comprender mejor cómo tienes que expresar tu búsqueda, y ajustarla a la sintaxis de SQL.
Ahora, vamos a buscar.
Por fin vamos a construir nuestra búsqueda. Para ello es necesario comprender algunos elementos que son importantes. Lo primero es entender dos clausulas básicas: SELECT y FROM.
SELECT. En realidad hace exactamente eso, seleccionar datos con los que trabajar. No se dedica a actualizar, eliminar o insertar. En la mayoría de ocasiones se emplea para seleccionar el nombre del campo con el que trabajar. Si se desea consultar varios campos, se separan por comas. Si se desea consultar todos los campos de una tabla se usa *. Se puede refinar SELECT añadiéndole *, tal y como hicimos en la primera consulta de esta entrada, y, después, decidir qué campo es el que te interesa.
FROM. Sirve para indicar el nombre de la tabla, generalmente, de la forma `table_name`, aunque, en ocasiones, puede ser `database_name`.`table_name`. Lo que acabamos de hacer se denomina periodo, y se pueden emplear, entre otras cosas, para unir bases de datos, tablas y campos en búsquedas concretas. En realidad esto sólo se hace cuando se consultan varias bases de datos y varias tablas.
En las consultas, la expresión más habitual es WHERE.
WHERE. Se emplea para limitar. Se puede usar un solo WHERE (ver AND/OR más adelante), como veremos en el siguiente ejemplo. En él se emplea WHERE para especificar que sólo queremos aquellos libros publicados en 2015. Observa que no hemos especificado el campo `publication_date` con SELECT. Una búsqueda se puede referir a cualquier campo en cualquier tabla donde estés ejecutando la consulta.
SELECT title FROM books WHERE publication_date = '2015'; |
Con WHERE se pueden usar gran cantidad de operadores de comparación, tales como < > != <> !< !> <= >=. Aquí tienes una explicación bastante buena sobre el uso concreto de cada uno de ellos.
Además, se pueden usar operadores lógicos, como LIKE, IS NULL, IS UNIQUE, EXISTS y BETWEEN. Aquí tienes una explicación sobre el uso de cada uno.
Después de WHERE se puede usar AND, OR y NOT. Se consideran cláusulas de WHERE porque no se pueden usar sin esa expresión.
AND. A todos nos resulta bastante conocido su uso. Se pueden emplear tantos como sean necesarios para la búsqueda. Imagina que deseas hacer una consulta de todos los documentos publicados en 2015 por la editorial Simon & Shuster:
SELECT title FROM books WHERE publication_date = '2015' AND publisher = 'Simon & Shuster'; |
OR. Al igual que le anterior, se pueden usar tantos como sean necesarios. Supón que necesitas localizar todos los libros que sean de 2015 o que estén etiquetados como nuevos:
SELECT title FROM books WHERE publication_date = '2015' OR location = 'new'; |
NOT. Al contrario que los otros operadores, NOT necesita que se emplea junto a WHRER, AND u OR. Si queremos los libros publicados en 2015 pero que no han sido colocados aún en el apartado de nuevos:
SELECT title FROM books WHERE publication_date = '2015' AND NOT location = 'new'; |
También se puede emplear != o <>, de la forma location != ‘new’.
Evidentemente, se pueden anidar AND, OR y NOT dentro de paréntesis. Si queremos algo de la editorial Simon & Shuster de 2015, pero no tenemos claro si lo han escrito así o de la forma “Simon and Shuster”, la ecuación sería:
SELECT title FROM books WHERE publication_date = '2015' AND (publisher = 'Simon & Shuster' OR publisher='Simon and Shuster'); |
Existen otros dos elementos que permiten gestionar los resultados de manera muy eficaz:
LIMIT. Permite controla la cantidad de resultados a visualizar tras una búsqueda. Un límite de 25 es bastante aceptable. E, incluso, puedes poner un límite de 0,25 (SQL comienza a contar en el 0). Si necesitas más registros, tan solo tienes que volver a ejecutar la misma consulta, pero indicando el límite 26, 50 para obtener el siguiente conjunto. Este mecanismo es muy útil cuando lo que necesitas es sólo un grupo de documentos de muestra. De esa forma no saturas el servidor.
En los ejemplos que se han empleado aquí, phpMyAdmin aplica automáticamente LIMIT 0, 30 siempre y cuando no se personalice esta opción. En mi trabajo suelo hacer LIMIT 0, 1000 y, después 1001, 2000. Si el servidor con el que estás trabajando tiene mucha carga de trabajo, lo mejor es limitar a números bajos.
ORDER BY. Permite especificar qué hacer con los resultados. Al igual que la clausula WHERE, no es necesario que aparezca en la lista de campos que has seleccionado. La ordenación puede ser ascendente (ASC, que se hacer por defecto) o descendente (DESC).
SELECT title FROM books WHERE publication_date = '2015' OR location = 'new' ORDER BY publication_date DESC; |
A modo de resumen
Esto es todo. Ahora vamos a recordar lo esencial.
- Para construir una ecuación de búsqueda en SQL, lo primero que necesitas es saber un poco sobre cómo es la base de datos que estás consultando.
- Luego, ten claro lo que quieres. Localiza en qué tablas y campos puede encontrarse esa información.
- Anota todos tus pasos y la información que pueda ser importante
- y, para finalizar, refina la búsqueda teniendo en cuenta las opciones de sintaxis que ofrece el lenguaje.
En próximos tutoriales trataré cosas como “cómo puedo obtener datos de dos tablas” o “¿qué es una llave?”. Aunque creo que serán entradas más cortas que esta, y seguramente harán referencia a ella. Existen gran cantidad de sitios con información parecida, pero no abordan el tema de la manera que yo pretendía aquí. No obstante, espero que esta sea una buena referencia para vosotros. Lo que realmente intento es que, con este tutorial, SQL sea algo menos confuso.

Deja una respuesta