Cómo crear un fichero robots.txt
Desde el punto de vista técnico, el fichero robots.txt es un archivo de texto en formato ascii, por lo que se puede crear desde cualquier editor de texto simple (bloc de notas, wordpad…). Suele ser muy recomendable emplear cualquier tipo de plantilla de las que existen en la web para ayudar en su creación. Entre ellas:- Robots.txt File Generator
- Robots Text Generator Tool, de Internet Marketing Ninjas
- Robots.txt Generator, de SmallSEOTools
- Robots.txt Generator, de Ryte
- O las aplicaciones con las que cuenta Google Webmasters Tools o Bing Herramientas para administradores de web.
¿Dónde se debe poner el archivo robots.txt?
Siempre debe estar en la raíz del servidor. En un sitio web genérico, si tu sitio es www.ejemplo.es debería aparecer si tecleas http://www.ejemplo.es/robots.txt. Hay que tener en cuenta dos elementos claves en este sentido. Por un lado que el sitio no tenga url canónica y, por lo tanto, exista también el sitio http://ejemplo.es. Por otro, que el sitio también tenga un servidor seguro: https://www.ejemplo.es. En ambos casos el fichero robots.txt debería ser el mismo y, por lo tanto, se tendría que duplicar en estos servidores.Sintaxis de robots.txt
El contenido de estos ficheros se pueden organizar en bloques, formados por directivas, cada una de las cuales comienza con el agente de usuario. Ese agente de usuario es el nombre de la araña a la que se dirige la instrucción que se está dando. El fichero, por lo tanto, puede tener un único bloque para todos los robots (para ello se emplea un asterisco) o bloques concretos para cada uno de los motores de búsqueda. Esto último suele ser común si lo que se desea es establecer directivas concretas para que los robots de spam (tanto de contenido como de correo electrónico) no dancen a sus anchas por el sitio web. El aspecto que tendría una directiva para todos los robots podría ser esta:User-agent: * Disallow: /con ella se le está diciendo a todos los robots de búsqueda que no deseamos que se indexe ningún contenido del sitio web. Las directivas (Disallow, Allow y User-agent) se pueden escribir tanto en mayúscula como en minúscula. Sin embargo, el valor que se indique a continuación sí deben respetar la forma en la que se ha escrito en el servidor, ya que no es lo mismo el directorio usuario que Usuario.
Directiva User-agent
Sirve para indicar la araña a la que se quiere dar la orden. Aunque la mayoría de arañas tienen una denominación larga, por ejemplo la denominación de la araña de Bing es Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm), la directiva User-agent la reconocerá como User-agent: Bingbot. Los servicios de búsqueda de información en la web suelen tener varios tipos de araña, cada uno especializado en un tipo de información. Por ejemplo, Bing cuenta con Bingbot, MSNBot, MSNBot-Media, AdldxBot y BingPreview; Google tiene a Googlebot, Googlebot-Image, Goolgebot-Video… Los 10 bots más importantes, según Imperva Incapsula son: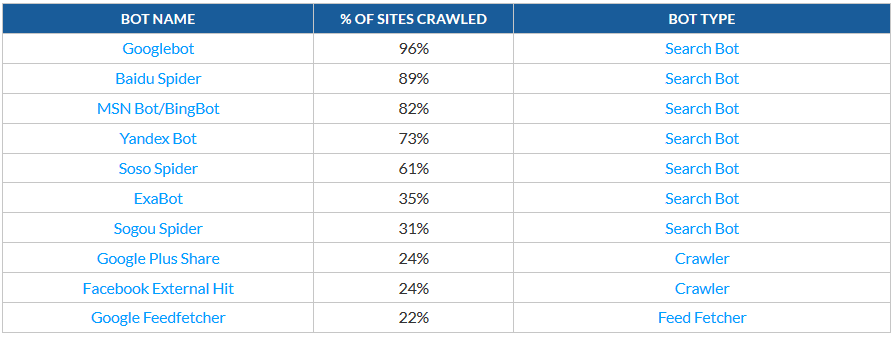
Directiva Disallow
Esta orden, que se puede repetir tantas veces como se desee (para varios ficheros o directorios), especifica qué partes del sitio web no deseamos que sean leías por la araña. Una peculiaridad de esta directiva es que si no se pone nada a continuación, en realidad estás permitiendo que se lea todo el contenido. Así, la ordenUser-agent: * Disallow:/Impide que cualquier araña lea el contenido del sitio web completo. Pero
User-agent: * Disallow:Permite que se pueda leer todo el contenido. La orden
User-agent: googlebot Disallow: /usuarioimplica que no se permite a la araña de Goolge leer el contenido que cuelga del directorio usuario.
Directiva Allow
Sirve para indicar que queremos que se lea un fichero o carpeta en concreta. Realmente puede llegar a no tener mucho sentido, ya que robots.txt es inclusivo. Es decir, que si no se especifica claramente que no quieres que se haga una cosa, por defecto, hará algo. Es decir, que todo lo que no sea Disallow será Allow. Sin embargo, si queremos dejar claro que necesitamos que se lea un documento en concreto, la orden será:Allow: /index.php
Directiva crawl-delay
Se emplea para indicarle al robot de indexación el tiempo que debe transcurrir desde que llega al sitio web hasta que comienza con el proceso de rastreo. Se suele emplear para ahorrar ancho de banda en determinados momentos. La ordenUsert-agent: googlebot crawl-delay: 15indica que el robot de Google debe esperar 15 segundos antes de comenzar a realizar su rastreo. No conviene emplear este método si no se tiene muy claro el motivo. Ralentizar el tiempo que está el robots de búsqueda en nuestro sitio afecta directamente al crawl budget, es decir, el tiempo que tiene destinado un robot concreto para indexar nuestro sitio. Cuando llega ese tiempo el robot se irá, aunque no haya indexado todo el contenido.
Directiva sitemap
Aunque no es una directiva que empleen todos los agentes, lo cierto es que los más importantes sí la emplean (Bing, Google y Yandex) y sirve para indicar dónde se encuentra el fichero sitemap.xml Esta captura del fichero robots.txt del periódico Ideal muestra la dirección donde se encuentran los ficheros sitemap.xml del servidor. Como se puede observar, es posible indicar varios ficheros, si es el caso.
Esta captura del fichero robots.txt del periódico Ideal muestra la dirección donde se encuentran los ficheros sitemap.xml del servidor. Como se puede observar, es posible indicar varios ficheros, si es el caso.
Uso de comodines
Aunque no existe una directriz clara en el documento que regula la forma en la que trabaja el Protocolo de Exclusión de Robots con respecto a las expresiones regulares o los comodines, lo cierto que es que la mayoría de robots de búsqueda entienden que el asterisco (*) sustituye a una cadena indeterminada de caracteres, y que el signo del dólar ($) indica que se trata del final de una URL. De esta forma:Allow: /*.phpindica que permitimos que todos los documentos que tengan cualquier cadena de caracteres y, a continuación .php, se pueden indexar. Pero, si observamos por ejemplo que contamos con ficheros con la finalización .php?=temp también serían indexados. Para evitar eso, y asegurarnos de que realmente sólo queremos los que terminan en .php deberíamos escribir la directiva de esta forma:
Allow: /*.php$Ojo a los siguientes fallos Suele ser muy común que se comentan una serie de errores que tendrán su repercusión directa en la forma en la que se posiciona nuestro sitio web. Los errores más comunes que he detectado cuando mis alumnos generan estos ficheros son:
- Emplear el robots.txt que genera automáticamente el CMS sin preocuparse de si hace mención a directorios importantes o que, por el desarrollo natural del sitio web, ha ido apareciendo o desapareciendo.
- No codificar el fichero en UTF-8. Si no se emplea este sistema de codificación de caracteres es posible que algunos robots tengan problemas para leer el fichero.
- Hacer ficheros demasiado grandes. Eso conlleva mucho tiempo de lectura, lo que reduce el tiempo que dedica el robots para hacer realmente lo importante: leer nuestro sitio web e indexarlo correctamente.
- Con la orden Disallow solo indicamos que no queremos que se lea una página, pero sí puede aparecer la URL de esa página en la lista de resultados de los buscadores, por el hecho de estar referenciada en otra página que sí se haya indexado. Para evitar que la página aparezca en los resultados de búsqueda lo ideal es emplear <meta name=»robots» content=»noindex»/>
- Google suele añadir un slash (/) al comienzo de las URLs. Esto significa que la orden Disallow: -user será leída por Google com Disallow: /-user, pudiendo referirse a otra cosa diferente de lo que deseamos. Lo mismo sucedería con la orden Disallow: *.pdf
- No es recomendable bloquear la lectura de archivos de hojas de estilo (CSS) ni de JavaScript (JS), ya que los robots sí son capaces de leer e interpretar esas etiquetas.
- Siempre es recomendable comprobar la integridad del fichero robots.txt creado. Para ello existen varias herramientas gratuitas online. Entre ellas, siempre suelo recomendar la de Google.

Deja una respuesta