La mejor forma de entender la aparición y la importancia que han adquirido los Sistemas de Gestión de Contenido (en adelante CMS) es conocer cómo se trabajaba antes de que estos surgieran.
Desde el punto de vista físico, los primeros sitios web estaban formados por ficheros HTML, archivos gráficos y otro tipo de formatos (principalmente pdf) que se solían organizar en carpetas dentro del servidor. Lo habitual era que esas carpetas se llamaran de forma similar al contenido que tenían. Así, por ejemplo, si dentro de la carpeta productos se añadían los ficheros en html de cada uno de los productos que se vendían (sillas.html, armarios.html, mesas.html…) se producía una URL de la forma http://www.ejemplo.com/productos/sillas.html. Era un mecanismo que tenía dos ventajas fundamentales. Por un lado tener todo el contenido del sitio web bien organizado ya que, en vez de un listado enorme de ficheros sueltos “colgando” de la raíz del sistema, se tenía un conjunto de directorios que especificaban claramente una estructura organizativa. Por otro, era un mecanismo muy socorrido para poder contar con URLs amigables, lo que favorecía el proceso de recordar las direcciones por parte de los usuarios.
Desde el punto de vista del contenido, este relacionaba unos ficheros con otros por medio de enlaces sencillos, que podían ser contextuales o proceder del sistema de navegación (fundamentalmente los menús principales), con lo que la organización de esa información era muy simple. Especialmente si se contaba con un número reducido de ficheros. Si el sitio web crecía, el “monstruo” se hacía cada vez más ingobernable.
En la época de la Web 1.0, cuando los sitios eran estáticos, existían una serie de problemas que se repetían con bastante asiduidad. El primero de ellos estaba relacionado con el contenido mal gestionado. Si la web crecía mucho, o si ésta era alimentada por varias personas en paralelo con poca coordinación, existía la posibilidad de que la información se repitiera, de tal forma que o bien aparecía el mismo contenido en varios puntos diferentes del sitio (es decir, en varios ficheros), o bien había contenido repartido en varios archivos, que estaba relacionado temática o conceptualmente entre sí, pero que no se vinculaba correctamente.
Otro problema surgía a la hora de editar el contenido de los ficheros que se encontraban en el servidor. Al estar colgado en un servidor web, lo normal era acceder a él por medio de un cliente FTP, descargarlo en el ordenador cliente, editarlo, guardarlo y luego volver a subirlo vía FTP. Los servidores web no facilitaban mucho la edición de los ficheros que almacenaba. Es cierto que este proceso se podía realizar online por medio del comando vi (una llamada al editor de textos en Unix y/o Linux) o similar, pero eso ya hacía que el proceso de edición fuese más lento y complicado. Aunque esta circunstancia se solucionó en parte con la aparición de editores que, además de tener la posibilidad de trabajar en modo WYSIWYG (What You See Is What You Get), algo que facilitaba mucho el proceso de diseño y creación de una página, contenían incorporado un cliente FTP que facilitaba la gestión de subida y bajada de ficheros. En esta época apareció Dreamweaver, de la empresa Adobe, que durante muchos años fue el editor estrella en el mundo web.
La cosa se complicaba aún más cuando varias personas querían trabajar sobre el mismo fichero al mismo tiempo, cosa que solía suceder con bastante frecuencia. Al problema evidente del acceso concurrente a un mismo fichero desde dos clientes diferentes se le suma el del control de cambios. Es decir, no existía un mecanismo que permitiera conocer los cambios que alguien realizaba sobre un fichero determinado. En muchos casos se terminaba sobrescribiendo un fichero sobre otro, perdiendo gran parte del trabajo. La nula gestión de versiones implicaba otro problema, y era la desaparición de los elementos de identificación de la autoría.
 Si estas situaciones eran incómodas, y convertían un trabajo en principio sencillo en algo comprometido, todo se complicaba aún más cuando se decidía cambiar el aspecto del sitio. Para este proceso se debía alterar el diseño de todas y cada una de las páginas que conformaban el sitio. En 1996 aparece la primera versión de CSS (Cascading Style Sheets, Hojas de estilo en cascada), lo que facilitó este trabajo de manera radical. Gracias a este mecanismo, todas las páginas se enlazan a un fichero CSS que especifica las características de formateo, colores, tamaños, tipos de letra, etc., de tal manera que si se desea cambiar el diseño del sitio web entero sólo será necesario modificar la hoja de estilo, y dichos cambios se reflejarán automáticamente en todas las páginas que estén vinculadas a ella.
Si estas situaciones eran incómodas, y convertían un trabajo en principio sencillo en algo comprometido, todo se complicaba aún más cuando se decidía cambiar el aspecto del sitio. Para este proceso se debía alterar el diseño de todas y cada una de las páginas que conformaban el sitio. En 1996 aparece la primera versión de CSS (Cascading Style Sheets, Hojas de estilo en cascada), lo que facilitó este trabajo de manera radical. Gracias a este mecanismo, todas las páginas se enlazan a un fichero CSS que especifica las características de formateo, colores, tamaños, tipos de letra, etc., de tal manera que si se desea cambiar el diseño del sitio web entero sólo será necesario modificar la hoja de estilo, y dichos cambios se reflejarán automáticamente en todas las páginas que estén vinculadas a ella.
La aparición de las bases de datos cambió radicalmente la forma en la que se creaban los sitios web y, por ende, la manera en la que se gestionaba el contenido. El poder contar con una herramienta que permitiera almacenar la información facilitó la posibilidad de poder separar contenido de formato físico. Aunque este hecho no fue algo que se produjera de manera radical y en todos los aspectos, sino que más bien fue una introducción progresiva. Los primeros sitios web empleaban las bases de datos como mecanismo para dar soporte a grandes cantidades de información que, en muchas ocasiones, aparecía de forma paralela junto a ficheros HTML. Poco a poco fueron surgiendo mecanismos que permitían una integración global.
Al mismo tiempo que esto surgía, y de forma paralela, la mayoría de empresas de todos los sectores transformaron su forma de ver y de estar en la Web. La filosofía que al principio tenían la mayoría de compañías con respecto a la Web se podía definir con la frase «no sabemos para qué, pero sí sabemos que hay que estar». El efecto que tenía esta forma conservadora de contemplar a la Web era que, desde el punto de vista técnico, se requería de poca infraestructura, ya que lo que se pensaba ofrecer se limitaba a una simple información corporativa, de productos, y poco más. Sin embargo, aspectos como el comercio electrónico, la implantación cada vez más progresiva de la Web en la vida cotidiana y la expansión de esta nueva forma de comunicación, lograron hacer variar esta visión, contemplando a la Web como una parte de la estrategia de comunicación y marketing corporativo y, más adelante, como otra manera de vender productos saltándose intermediarios.
Claro está que esta forma de entender la Web no se podía implementar con un grupo de ficheros HTML. Era necesario contar con una infraestructura tecnológica que aportara más dinamismo y más opciones a la hora de gestionar el contenido, los productos y la información que se ofrecía a los potenciales usuarios/clientes. Este camino también llevaba a las bases de datos.
Tradicionalmente se ha considerado que las tres empresas pioneras en la introducción de bases de datos en sus sitios web han sido Illustra Information Technologies, RedDot y Vignette Corporation. La primera de ellas, Illustra, comercializaba un software servidor que facilitaba la gestión de datos (fundamentalmente multimedia) denominado Illustra Server. Al estar familiarizados con el uso de bases de datos relacionales en general, y aquellas basadas en SQL en particular, en la empresa se optó por su empleo como método para organizar la información de la web corporativa que lanzaron en 1994. Lamentablemente no es posible localizar ya ninguna imagen de la web pionera, ya que en 1996 la empresa fue adquirida por Informix (hoy IBM Informix) y toda la información se centralizó en la web de la nueva empresa, desapareciendo también el dominio en el que se hospedaba.
RedDot fue una compañía fundada en 1993 que creó InfoOffice, una aplicación web para Windows que permitía gestionar contenido en un entorno web. El año siguiente, y con el fin de hacer más mnemotécnico el nombre del producto, se cambia a RedDot CMS (haciendo mención a los dos puntos que indicaban el lugar a partir del cual un contenido se podía editar). Se trató del primer programa que permitía editar contenidos web en una interfaz casi idéntica a la empleada para visualizar esa página en un navegador. Se estaban sentando las bases de los CMS.
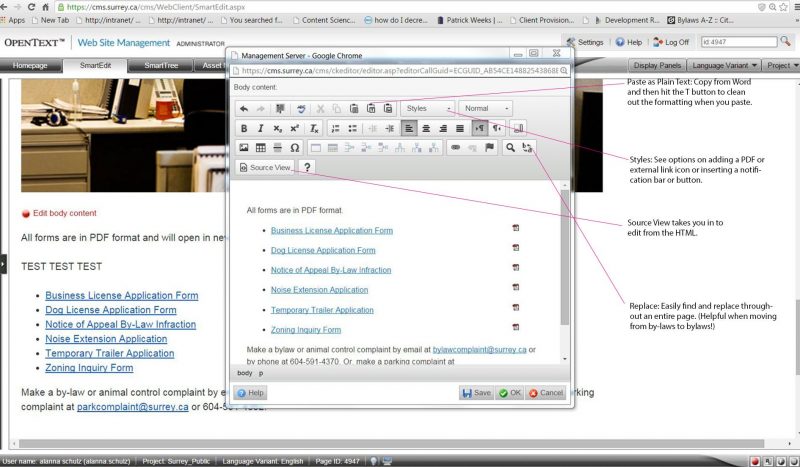
La vida de RedDot desde entonces fue bastante ajetreada. La empresa RedDot fue adquirida en 2005 por la empresa canadiense Hummingbird, uno de los buques insignia de las TIC que, a su vez, fue comprada en octubre de 2006 por OpenText.
 En 1995 eran varias las empresas que se valían de técnicas similares a las empleadas por RedDot e Illustra para gestionar el contenido. De todas ellas destacaba CNET, compañía dedicada a la difusión de información de corte tecnológico (web, música, videojuegos, etc.). Para facilitar el proceso de creación de contenido contaban con un programa, llamado Prisma. Ese mismo año Ted Schadler, creador de Vignette Corporation, se pone en contacto con CNET para fusionar Prisma con un software que estaba desarrollando que era capaz de realizar un proceso similar, pero con muchas más funcionalidades. De esa unión apareció Vignette V7 Application Services, un gestor de sitios web que, por medio de varios paquetes de software, facilitaba el proceso de creación, edición, gestión del flujo de trabajo y publicación de contenido en la web. En 2009 OpenText adquiere Vignette Corporation, con lo que la misma empresa es ahora poseedora de los dos CMS pioneros: RedDot CMS y Vignette v7.
En 1995 eran varias las empresas que se valían de técnicas similares a las empleadas por RedDot e Illustra para gestionar el contenido. De todas ellas destacaba CNET, compañía dedicada a la difusión de información de corte tecnológico (web, música, videojuegos, etc.). Para facilitar el proceso de creación de contenido contaban con un programa, llamado Prisma. Ese mismo año Ted Schadler, creador de Vignette Corporation, se pone en contacto con CNET para fusionar Prisma con un software que estaba desarrollando que era capaz de realizar un proceso similar, pero con muchas más funcionalidades. De esa unión apareció Vignette V7 Application Services, un gestor de sitios web que, por medio de varios paquetes de software, facilitaba el proceso de creación, edición, gestión del flujo de trabajo y publicación de contenido en la web. En 2009 OpenText adquiere Vignette Corporation, con lo que la misma empresa es ahora poseedora de los dos CMS pioneros: RedDot CMS y Vignette v7.
Desde ese momento la industria se ha movido alrededor de los CMS con bastante soltura, apareciendo, fusionando y haciendo desaparecer continuamente empresas, programas, estrategias de mercado, etc. Se trata, sin duda, de un mercado muy dinámico al que es difícil seguir la pista.

Deja una respuesta