Cuando se va a iniciar cualquier tipo de investigación o, simplemente, se quiere hacer un análisis para conocer cómo se encuentra un disciplina, teoría, o idea en concreto, uno de los primeros pasos siempre se centra en la búsqueda de información. La mayoría de nosotros tenemos la tendencia natural de emplear para ello índices de citas, que permiten conocer el impacto que ha tenido un trabajo previo en la comunidad científica. Sin embargo, en la actualidad existen muchas otras herramientas que pueden resultar muy útiles para el descubrimiento de nueva literatura científica.
Entre estas herramientas se encuentran las que permiten realizar búsquedas específicas por autor, tema o campo de investigación, así como aquellas que utilizan técnicas de análisis de datos para identificar patrones y visualizar la información de manera más clara e intuitiva. Estas aplicaciones han demostrado ser muy prácticas para los investigadores, ya que les permiten acceder a una gran cantidad de información de manera rápida y eficiente, descubriendo documentos relevantes de manera mucho más sencilla que con el uso de los índices de citas.
Además, la mayoría de ellas han explorado un territorio hasta ahora obviado por los grandes de la industria, que continúan anclados en presentar los resultados de las consultas en largas, tediosas y nada atractivas listas de autores y/o títulos: la visualización de la información. Estas herramientas, al presentar las relaciones entre los documentos de forma visual e interactiva, facilitan la rápida comprensión de los campos de estudio, favoreciendo así la identificación de conexiones entre documentos que, de otra manera, serían mucho más difíciles de encontrar.
Evidentemente todo esto conlleva dos ventajas más: el ahorro de tiempo, ya que se agiliza mucho el proceso de búsqueda y análisis de documentos relacionados y el fomento de la colaboración, al facilitar la generación de nuevas ideas y enfoques a partir de una evidencia: la colaboración invisible, que es la que se produce entre investigadores que, sin conocerse o trabajar juntos, colaboran, por medio de sus investigaciones, en continuos avances dentro de una área del conocimiento común.
En esta entrada no pretendo hacer un análisis exhaustivo de todas ellas. De hecho, es posible que tampoco las recoja a todas. Lo que pretendo es que las personas interesadas (fundamentalmente mis alumnos) tenga un punto de partida a partir del cual poder localizar herramientas, presentadas de forma unificada, que les permitan avanzar en sus investigaciones de la forma más satisfactoria posible y, si se puede, ahorrando tiempo. De paso, podría lograr que dejen de usar la wikipedia como fuente de información fundamental 🙂
Connected Papers
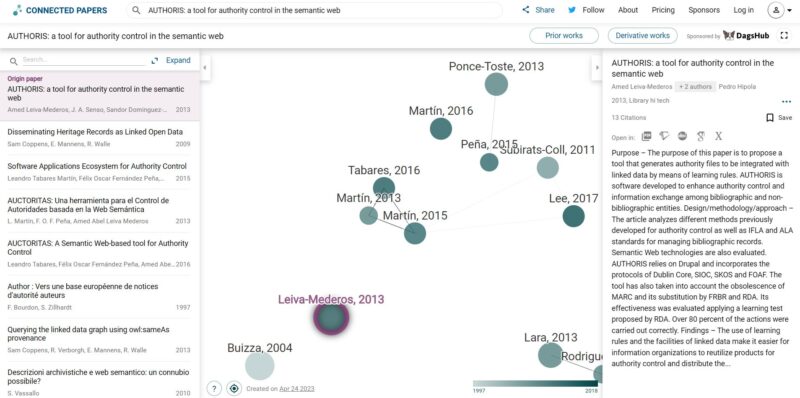
Se trata de una herramienta gratuita que permite tanto descubrir como explorar artículos científicos relacionados entre sí. Dichas relaciones las ofrece de manera visual, lo que facilita enormemente la comprensión de lo que se ve. Tras una consulta inicial, por medio del título de una publicación, su DOI, su identificador de arXiv o las URLs de Semantic Scholar o Pubmed, genera un gráfico interactivo que muestra la relación entre los documentos basándose en las citas y las referencias bibliográficas.
En ese gráfico, que no es más que un conjunto de nodos conectados por arcos que representan sus relaciones, los artículos se ordenan en función a la similitud, lo que representa el primer elemento fundamental en esta aplicación. Si no fuera así, sólo se mostrarían los documentos que están relacionados directamente entre sí por medio de las citas. Sin embargo, aplicando este método es posible relacionar documentos que no estén directamente citados entre sí pero sí conectados temáticamente. Para ello se emplea como métrica de similitud la co-citación y el acoplamiento bibliográfico (cuantas más referencias comunes tengan X documentos, mayor probabilidad existirá de que traten de lo mismo, por lo que la distancia que debe haber entre ambos en el grafo debe ser menor).
A mi parecer, el segundo elemento importante con el que cuenta esta herramienta es la gestión de la actualidad de la información. Con la idea de tener información precisa sobre cuán actualizadas están las publicaciones que aparecen en el gráfico, se emplean diferentes codificaciones de colores para especificar qué artículos son relativamente actuales en relación al documento que ha iniciado la búsqueda.
|
Nombre |
Connected Papers |
|
Dirección |
|
|
Fuente de datos |
Semantic Scholar (más de 200 millones de papers) |
|
Opciones de búsqueda |
Palabras clave Título DOI URL de arXiv, Semantic Scholar o PubMed |
|
Filtrado |
No cuenta con opciones de filtrado de los resultados |
|
Opciones de visualización |
– El tamaño del nodo indica la cantidad de citas – Se indica la fecha con colores. Los más oscuros son los más recientes – Los nodos conectados con líneas indican mayores conexiones temáticas – Genera una tabla con los papers que se citan con más frecuencia, que se puede descargar en bibtex – Genera una tabla con los trabajos derivados, que se puede descargar en bibtex – acceso rápido al resumen de cada uno de los papers que forman los nodos, así como al texto completo en pdf y a su enlace en Google Scholar, arXiv o Semantic Scholar |
Litmaps
Es, posiblemente, una de las herramientas gratuitas que más opciones ofrece en la actualidad. De hecho, son tantas que se escapan a los objetivos de esta primera aproximación. Una vez dados de alta permite:
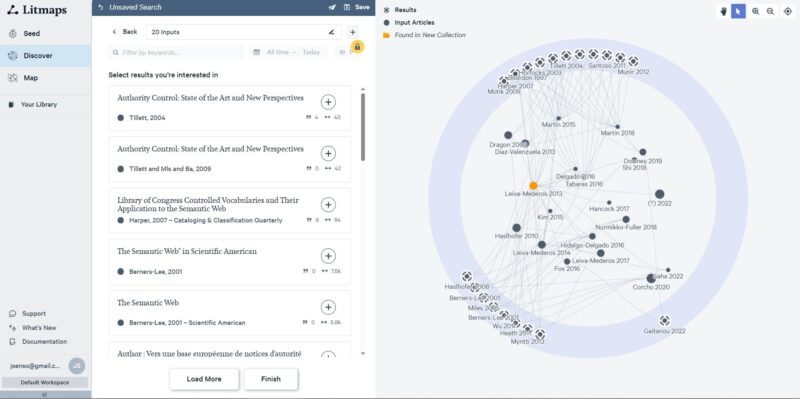
– Seed: se genera un mapa de relaciones entre papers basándose en las citas y en las citas de estas citas, en las que el artículo que se emplea como origen de dicho mapa se denomina como esta opción: seed. Sirve para ubicar el artículo originario de este grafo dentro del panorama de la disciplina en cuestión. Dentro del gráfico, aquellos nodos que aparecen a la izquierda del seed son los citados en el artículo, mientras que los que aparecen a la derecha son los que lo citan a él. El tamaño de los nodos puede depender de la cantidad de citas recibidas, la cantidad de referencias con las que cuenta el artículo, la relevancia en el mapa o el “momentum” (recuento de citas ajustado a la fecha de la publicación).
– Discover: permite introducir uno o varios documentos como referencia. A partir del análisis de esa información genera un mapa que estará rodeado por uno o dos círculos exteriores. Los nodos que se encuentran en el primer círculo exterior corresponden a artículos que se deduce que pueden complementar a los previamente referenciados sobre la base de, solo, las citas inmediatas. El segundo círculo, al que sólo se puede acceder en la versión de pago, aparecerán los nodos de las sugerencias a partir del análisis de las citas de las citas.
– Map: si en la fase anterior se han señalado varios artículos, en esta modalidad mostrará todos los nodos de esos artículos relacionados entre sí, a modo de mapa de citaciones. Ese mapa también se puede crear a partir de las referencias bibliográficas que se encuentren almacenadas en cualquier gestor de referencias bibliográficas previa importación de registros.
|
Nombre |
Litmaps |
|
Dirección |
|
|
Fuente de datos |
Semantic Scholar, Crossref y OpenAlex |
|
Opciones de búsqueda |
Palabras clave Título DOI PubMed ID PubMed Central ID Semantic Scholar ID OpenAlex ID Comillas para expresiones literales Operador de negación (-) Operador de intersección (+) Operador de unión (|) Paréntesis para agrupar términos Truncamiento (*) |
|
Filtrado |
Filtrado de los resultados por medio de palabra clave, fecha y (sólo disponible en discovery y, además, en la versión pro) profundidad del análisis. Filtrado de los resultados de los gráficos en función a las citas recibidas, referencias incluidas en el trabajo, momentum o relevancia en el mapa. La interpolación de las fechas puede ser logarítmica o lineal. |
|
Opciones de visualización |
Todos los registros generados, en cualquiera de las opciones de búsqueda, se pueden almacenar en bibtex. Informa tanto de las citas como de las referencias de cada paper de manera individual. Es posible recentrar el mapa con el uso de un botón específico. Se puede hacer zoom por medio de dos botones específicos. El grafo generado en la opción map se puede exportar y/o compartir |
Iris.ai
A través de esta herramienta se pueden realizar dos tipos de análisis:
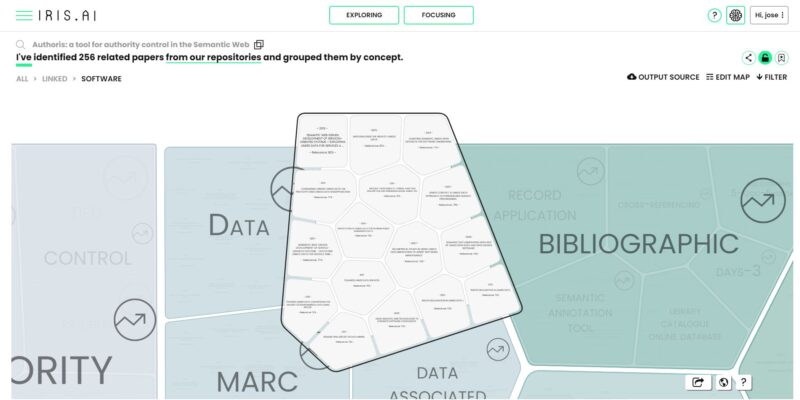
– Exploring: se inicia la búsqueda con una URL que se emplea como documento de muestra. A partir de él se muestra la relación que tiene con otros recursos pero, en vez de mostrar dicha relación por medio de un grafo, en esta ocasión se emplean clústers temáticos.
– Focusing: requiere la introducción de una serie de términos, a modo de título, una breve descripción del problema central del estudio y una colección de bookmarks previamente almacenados en el sistema. A continuación aparecerán diversas preguntas para refinar el conjunto de datos con los que trabajar y, para finalizar, se genera un mapa de documentos relacionados y propuestos.
Las principales deficiencias de esta herramienta:
– Posiblemente el uso de clústers no sea la opción de visualización más acertada para mostrar relaciones entre documentos.
– La usabilidad del sistema deja mucho que desear.
– Es un software de pago. Sólo permite 10 días de prueba.
– En ningún momento queda clara la relación de repositorios que se emplean o que se pueden filtrar.
|
Nombre |
Iris.ai |
|
Dirección |
|
|
Fuente de datos |
Múltiples repositorios, pero sin indicar cuáles de forma clara |
|
Opciones de búsqueda |
URL de artículo Se puede proponer un título a modo de búsqueda inicial Se puede proponer un problema de investigación Es posible usar documentos como referencia para hacer búsquedas como el ejemplo |
|
Filtrado |
Por fecha Por repositorio (pero no aparece la forma normalizada para usarlo) |
|
Opciones de visualización |
En clústers temáticos con nodos de difícil visualización al final del clúster. |
Open Knowledge Maps
Creado por la organización homónima auspiciada por la Comisión Europea. La herramienta genera mapas de conocimiento a partir de la introducción, fundamentalmente, de palabras clave.
Los mapas se crean a partir de los 100 documentos más relevantes para los términos de búsqueda. Dicha relevancia se obtiene a partir de criterios basados en la similaridad. Una vez hecho esto, se crea un mapa de conocimiento basándose en los metadatos (utiliza el motor de búsqueda BASE para ello). Los papers que tienen más palabras en común se agrupan, si la búsqueda se ha hecho sobre BASE, formando nodos que usan la metáfora del tamaño para indicar aquellos que tienen más documentos asociados. Si la búsqueda se ha hecho sobre PubMed se usan las citas como elemento para definir el tamaño de los nodos.

|
Nombre |
Open Knowledge Maps |
|
Dirección |
|
|
Fuente de datos |
BASE (Bielefeld Academic Search Engine) con más de 320 millones de documentos |
|
Opciones de búsqueda |
Palabra clave |
|
Filtrado |
Documentos Open Access Ordenación por relevancia, título, autor y fecha |
|
Opciones de visualización |
Exportación de resultados en bibtex. Información clara sobre cantidad de documentos usados para el mapa, tipos documentales y calidad de los datos. Muestra detalles sobre tipo de documento, formato, opciones de cita, área de conocimiento… de cada uno de los documentos empleados para la generación del mapa. |
ResearchRabbit
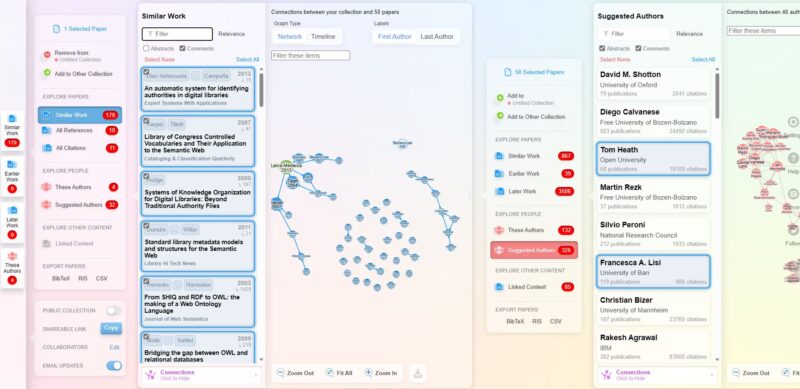
Posiblemente una de las herramientas que más éxito está teniendo, al abrigo del boom por las aplicaciones basadas en inteligencia artificial. La búsqueda se puede iniciar a partir de un título, DOI, Identificador de Pubmed o a partir de una colección de Zotero (por cierto, tiene una integración muy buena con este gestor) o a partir de una referencia en formatos bibtex o RIS. A partir de ahí, comienza la magia: listado de trabajos similares a partir del análisis de las palabras del documento inicial y los autores, análisis de citas recibidas, exploración de otras obras de los mismos autores, listado de autores sugeridos… Posiblemente la mejor de las herramientas gratuitas de las disponibles en la actualidad.
|
Nombre |
ResearchRabbit |
|
Dirección |
|
|
Fuente de datos |
PubMed para fuentes biomédicas y Semantic Scholar para las demás |
|
Opciones de búsqueda |
Título, palabra clave, identificador de PubMed, bibtex, RIS y Zotero para comenzar la búsqueda. |
|
Filtrado |
Búsqueda por palabra en comentarios y/o resúmenes. Buscar sólo en colecciones públicas |
|
Opciones de visualización |
Red ordenada por conexiones entre autores o por línea de tiempo Numerosas opciones de exportación |
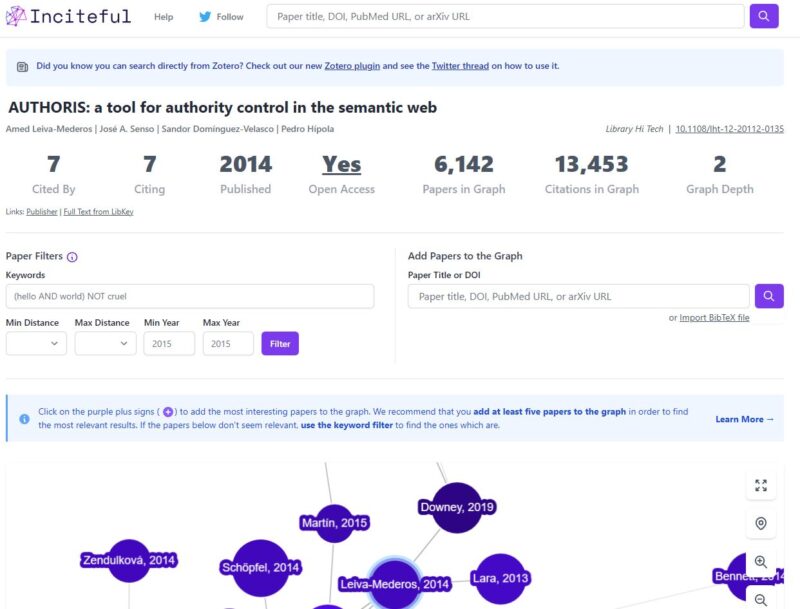
Inciteful
Presenta dos modalidades de búsqueda. Por un lado, mostrar una red generada a partir del análisis de un único documento, que generará un mapa con aquellos que son más relevantes en función a las citas recibidas y, por otro lado, muestra la conexión que existe entre dos documentos diferentes. Al igual que ResearchRabbit, se puede conectar a una colección de Zotero por medio de un plugin.
|
Nombre |
Inciteful |
|
Dirección |
|
|
Fuente de datos |
OpenAlex, Semantic Scholar, Crossref y OpenCitations |
|
Opciones de búsqueda |
Búsqueda por título, DOI, o las URLS de PubMed o arXiv. También es posible importar un fichero bibtex La búsqueda por materias activa un mecanismo de sugerencia de títulos, pero no de palabras clave. En el filtrado por palabras clave permite usar operadores booleano (AND, OR y NOT), así como el uso de paréntesis y truncamiento |
|
Filtrado |
Por palabra clave Por distancia mínima y máxima entre documentos Por fechas Es posible añadir paper al gráfico generado |
|
Opciones de visualización |
Gráfico de nodos donde el tamaño de cada nodo representa el número de citas recibidas. Muestra la conexión entre nodos por medio de las citas. Genera mapas individuales de cada uno de los nodos cuando se seleccionan. Permite la reubicación en el mapa Permite hacer zoom Los colores determinan la fecha de las publicaciones |
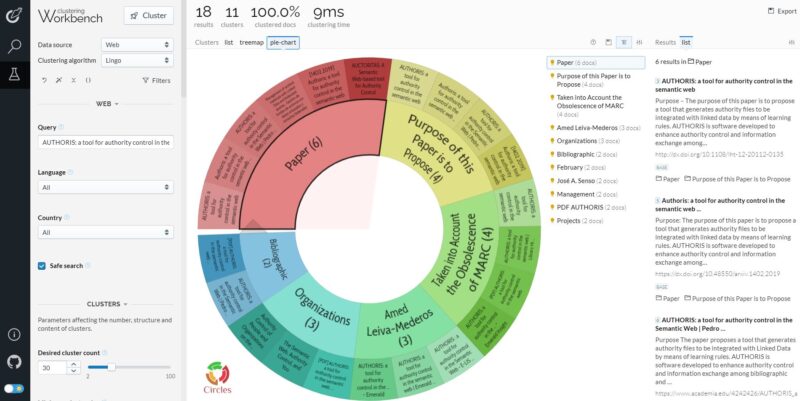
Carrot2
La búsqueda inicial se hace por palabras clave o sobre documentos de PubMed y, lo que más llama la atención, es que la única de las herramientas aquí descritas que permite limitar la búsqueda por idioma y/o país. No destaca por ser una herramienta de descubrimiento de nuevos documentos, sino más bien por ser una aplicación que permite realizar clústers temáticos a partir de un artículo o de un conjunto de documentos recuperados a partir de una búsqueda realizada con palabras clave. En ese sentido presenta más limitaciones como herramienta exploratoria de una disciplina.
|
Nombre |
Carrot2 |
|
Dirección |
|
|
Fuente de datos |
La web y PubMed (resúmenes) |
|
Opciones de búsqueda |
Al emplear el motor de búsqueda de ElasticSearch permite realizar todas las combinaciones clásicas de búsqueda: operadores booleanos, truncamiento, proximidad… aunque no cuenta con una ayuda que lo especifique |
|
Filtrado |
Los clústers que se generan son muy configurables: desde el tamaño, algoritmo de clúster, |
|
Opciones de visualización |
Permite personalizar el etiquetado de los elementos del clúster, hacer treemaps, exportar los gráficos resultantes… |
Deja una respuesta