Una de las claves para diseñar (o mantener) un sitio web está en escuchar qué es lo que el usuario espera de él. Evidentemente, no podemos ir a preguntarle a cada uno de ellos. Pero si tuviéramos una herramienta que permitiera saber cómo se mueve, qué palabras clave emplea para buscar dentro del sitio, cuánto tiempo está en cada página, cómo interactúa con los elementos que le ofrecemos… tendremos un mecanismo perfecto para conocer su comportamiento y sus necesidades de información y, con eso, poder adaptar el diseño, la estructura e, incluso, el contenido, a lo que espera encontrarse.
Una solución podría pasar por la realización de cuestionarios. Pero en un entorno tan complejo como la web, con usuarios de diversas procedencias, con diferentes intereses (aunque el sitio trate de un tema monográfico, habría que considerar las diferentes vertientes) esta solución tiene poco sentido. Además, siempre he pensado que la gente no suele contestar de manera sincera. Lo ideal es contar con una herramienta que no interfiera con el proceso natural de consulta o navegación, algo que permanezca latente, recogiendo datos, pero que el usuario desconozca. Eso existe, y se llama fichero log.
A estas alturas seguro que alguien piensa: para eso, emplea Google Analytics o alguna herramienta similar. A esa persona yo le diría: existe una gran diferencia entre los datos con los que trabaja uno y con los que trabaja otro. Y, sobre la base de esa diferencia, podemos decir que los datos de los logs son más puros y directos. Por cierto, una actualización de un trabajo como el de Systemadmin sería un gran TFG.
Analítica web en tiempo real vs ficheros log
La vertiente más empleada en el análisis de transacciones de sitios web es la analítica web en tiempo real. Es una técnica que permite monitorizar la información e indicadores del sitio web en el mismo momento en el que se producen. Sirve, entre otras muchas cosas, para descubrir cuáles son las tendencias actuales dentro de un sitio web.
Lo normal es que estas herramientas analicen indicadores relevantes, tales como la tasa de conversión (algo muy de marketing, que se refiere al cálculo de la cantidad de personas que cumplen el objetivo), tasa de rebote (cuando un usuario abandona tu sitio rápidamente), lealtad de los visitantes (algo complejo con las IPs dinámicas, por lo que cada vez más se emplean perfiles de usuario) o las páginas por visita (el clásico: la página más visitada/compartida/impresa…). Los reyes de la analítica web en tiempo real, a día de hoy, son Clicky, Woopra y Google Analytics.
El uso que se hace de estas técnicas está orientado, fundamentalmente, a analizar el comportamiento del usuario desde el punto de vista del marketing. Es decir, descubrir cuánto tiempo pasa un usuario en el sitio, qué le gusta más y cómo ha llegado hasta allí. Por estos motivos es muy importante que este proceso se realice en tiempo real.
El trabajo con ficheros log no requiere tanta inmediatez. No es necesario el tiempo real para el análisis que se produce. ¿Más diferencias? Para empezar, la cantidad de datos con los que se trabaja son mayores. Hay que tener en cuenta que se pueden combinar todos los ficheros log que se generan para sacar conclusiones. Los programas de analítica web en tiempo real sólo acceden a una pequeña porción de estos.
El trabajo con los ficheros log sólo se puede realizar con el visto bueno del administrador del sistema, ya que es el único que debería poder acceder a las entrañas del sitio web para capturarlos. Sin embargo, los programas de analítica web capturan los datos de manera remota por medio de rastreadores con ID de seguimiento, o por etiquetas..
La cantidad de datos recogidos en los ficheros logs los convierten en herramientas muy potentes para gestionar, no solo la navegabilidad del sitio, o conocer cómo busca el usuario, si no también la seguridad del sitio.
Hay un gran artículo, algo antiguo ya pero muy bueno para los que están empezando, que habla de esto: las diferencias de medición por logs y tags.
Cómo funcionan
Realmente no creo que haya que ponerse en plan fundamentalista con esto. Lo más probable es que todas las herramientas ayuden, y aporten su granito de arena en el proceso de evaluar el uso que se le da a un sitio web.
Los ficheros log se encargan de almacenar las transacciones que se realizan en un sistema. Hoy en día prácticamente todo genera un fichero log (sistema operativo, programas, apps del móvil…) y siempre queda un rastro escrito en algún sitio. El problema es que no todo el mundo puede acceder a ese sitio. En una web, por ejemplo, los ficheros log sólo serán accesibles para el administrador del sistema. Eso es lo que los convierte en herramientas importantes para cualquier análisis.
El análisis de un fichero log nos permitirá conocer quién nos visita y con qué frecuencia, cuánto tiempo está en cada página, qué necesidades de información tienen, si la estructura del sitio es la correcta o no, si el usuario tiene que desplazarse mucho o poco hasta llegar a donde quiere llegar, qué palabras clave emplea en las búsquedas internas… Un sin fin de opciones que ningún arquitecto de la información debería desdeñar.
Como mínimo, cualquier servidor web cuenta con la posibilidad de trabajar con tres ficheros logs diferentes pero, como veremos a continuación, pueden ser muchos más:
- El servidor web. Si trabajamos con Apache lo normal es que tengamos el log del sistema Access.log (su presencia se configura en el fichero httpd.conf) y el que almacena los errores: error.log (muy importante para conocer los mensajes 404, 301, 302, 303… y resolver los problemas).
- Si se usa un CMS (Drupal, WordPress…) es posible instalar algún módulo para la creación y gestión de estos ficheros. En Drupal, por ejemplo, a partir de la versión 7 existe Watchdog para gestionar los logs de sistema y de errores; en WordPress existen varios plugins para visualizar los ficheros de error y debug…
- Si se instala un sistema de búsqueda, es posible que cuente también con un querylog que almacena, entre otras cosas, las palabras clave empleadas por el usuario para consultar los documentos almacenados en el sitio.
Mención especial merece el log de la base de datos. Si se está utilizando MySQL hay que decir que es posible activar varios registros, todos ellos fundamentales: el de errores, el general de consultas, el binario y el de consultas lentas (las que han superado un tiempo determinado). Pero debes tener en cuenta algo importante: esos ficheros no paran de alimentarse, así que debes controlar su crecimiento. Para eso es bueno revisarlos con frecuencia, hacer copias de seguridad y eliminar los copiados, emplear las opciones SQL para reducir su tamaño…
Cómo trabajar con estos ficheros
La gran ventaja que tienen los logs es que son ficheros ASCII, con lo que su gestión es muy sencilla. Hay que tener en cuenta que, al dejar constancia de todas las transacciones del sitio, y dadas las características de la versión 1.1 del protocolo HTTP (recuerda, no existe el concepto de sesión), cada línea del fichero corresponderá a una petición realizada al servidor por parte del cliente.
Como desventaja tenemos que se trata de ficheros de gran tamaño (pero poco peso) y que es necesario preprocesarlos antes de sacar datos de ellos, ya que se suele cometer el error de analizar el fichero entero, cuando este suele incluir muchas líneas que no son relevantes. Al ser un proceso algo tedioso, lo mejor es automatizarlo.

La entrada típica de un fichero log es algo parecido a esto:
150.214.XX.XXX – – [07/Oct/2013:15:20:02 +0200] «GET /module/CLNEWMSG/css/bubble.css?1251290622 HTTP/1.1» 304 136 «http://cursos.jsenso.es/index.php?logout=true» «Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0»
Donde se puede ver una consulta realizada desde una IP concreta (que he enmascarado por razones de seguridad, pero que en el log se vería entera), la fecha y la hora de la consulta (la del servidor) el tipo de acción que se realiza GET (empleado en el http para obtener información, traer datos que se encuentran en el servidor en forma de archivo, base de datos…) o POST (empleado para enviar información desde el cliente para que la procese el servidor), los datos del recurso empleado, la versión del protocolo HTTP, el estatus, la respuesta, la versión del navegador e, incluso, la del sistema operativo.
Como se puede observar, la cantidad de información que se puede extraer es realmente muy valiosa, aunque hay que tener cuidado con varias cuestiones. Dado que en el protocolo HTTP no se trabaja con el concepto de sesión cada línea se trata como una petición independiente. Esto implica que, por ejemplo, si desde el cliente se usa el botón “atrás”, el navegador suele cargar una copia de la cache con el fin de ir más rápido y ahorrarse una petición al servidor. Esa acción no aparece en el log y la impresión que nos llevaremos es que el usuario va dando tumbos, sin seguir una línea de navegación clara.
La posible solución a este tipo pasa por establecer una serie de reglas de asociación con el fin de establecer vinculaciones entre las operaciones realizadas por un mismo usuario (que se identifican con la IP) durante un periodo de tiempo determinado y saber, de esta manera, el comportamiento dentro de una sesión “virtual”. El proceso lo explican muy bien Ortega y Aguillo (Ortega, José-Luis; Aguillo, Isidro F. “Minería del uso de webs”. El profesional de la información, 2009, enero-febrero, v. 18, n. 1, pp. 19-25). Pero claro, eso requiere de un conocimiento muy preciso del sito web y de su estructura. Y aún así, habría algún problema de identificación si el cliente está trabajando desde varios ordenadores a la vez.
Software
En realidad, al tratase de ficheros ASCII, el trabajo con log es bastante sencillo. Es muy fácil crear macros en cualquier procesador de textos que se encargue de hacer las depuraciones que se han comentado en este texto, más las propias de cada servidor, meter el contenido en una base de datos y, a partir de consultas sobre ella, obtener los datos que se necesitan.
No obstante, siempre es bueno conocer algunos programas específicos para el trabajo con estos ficheros. Aquí tenéis un listado de alguno de los que yo suelo recomendar:
- AWStats. Herramienta gratuita que sirve para analizar logs de servidores web, de correo electrónico y de ftp. Realiza un análisis muy bueno de los visitantes únicos y de las visitas que hacen los robots, que suelen generar cierto descontrol en los resultados.
- Free-SA. Está más pensado para la evaluación del rendimiento del servidor y su seguridad, pero da una resultados muy relevantes.
- Web Expert Lite. Es el que solemos usar en clase. Tiene cuatro versiones, pero par al trabajo diario es suficiente con la lite.
- W3Perl. Aplicación gratuita que se instala en el servidor. Está preparada para trabajar con Linux (Tarball, RPM, SRPM y Debian/Ubuntu), Windows (IIS, Apache, Abyss) y Mac. Tiene una versión para funcionar sin servidor (offline).
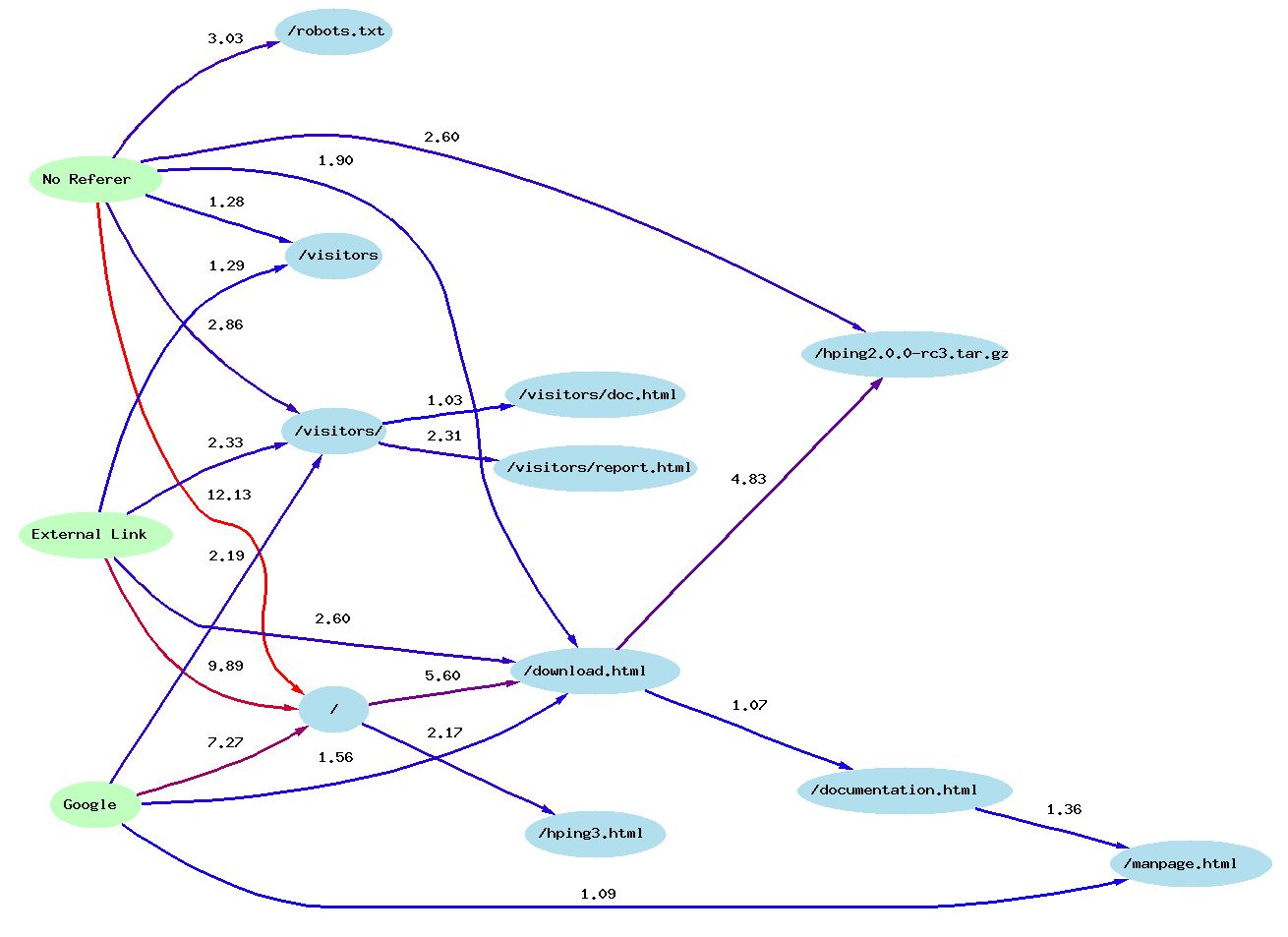
- Visitors. Es una forma diferente de trabajar con ficheros log, ya que lo que hace es generar un grafo con las conexiones realizadas por los usuarios. Aunque también ofrece un análisis estadístico y varios tipos de informes.
- The Webalizer. Algo desactualizado, pero sus informes son bastante buenos.
- AlterWind. Cuenta con dos versiones, la estándar, que contiene gran cantidad de análisis, y la professional, que dejan probarla durante 30 días.
- Si vas a trabajar en linux, un blog muy interesante sobre cómo trabajar con logs en este sistema operativo es: http://www.websecurity.es/analisis-los-ficheros-logsparte-iv

Deja una respuesta