En muchas oc asiones, cuando navegamos por la Web, o cuando buscamos en Google, nos encontramos con el famoso Error 404: Url not found. Para el usuario de a pie, este tipo de mensajes no son más que un incordio. Para el arquitecto de la información son pistas fundamentales que le permiten saber que en su sitio web hay un problema y, además, cómo tiene que solucionarlo.
asiones, cuando navegamos por la Web, o cuando buscamos en Google, nos encontramos con el famoso Error 404: Url not found. Para el usuario de a pie, este tipo de mensajes no son más que un incordio. Para el arquitecto de la información son pistas fundamentales que le permiten saber que en su sitio web hay un problema y, además, cómo tiene que solucionarlo.
Antes de hablar del por qué de esos famosos códigos, vamos a analizar en qué momento se producen. Para ello, hablaremos primero de cómo funciona el protocolo HTTP.
El funcionamiento de HTTP
Se trata de un protocolo que trabaja a nivel de aplicación, y que está soportado por los servicios de conexión TCP/IP. Su funcionamiento es idéntico al del resto de servicios de su entorno: el servidor está continuamente escuchando el puerto de comunicaciones TCP a la espera de que llegue una solicitud de conexión por parte del cliente HTTP (el navegdor, por ejemplo). En cuanto llega dicha solicitud el mismo protocolo TCP se encarga de mantener la comunicación y garantizar que el intercambio de datos se realiza sin errores. Es un proceso de solicitud/respuesta. El cliente establece una conexión con un servidor por medio de una solicitud (por ejemplo, el fichero index.html). El servidor responde con un mensaje que contiene el estado de la operación (si se encuentra ese recurso, si no aparece…) y el resultado (el fichero index.html) que el cliente procesa, interpreta y muestra al usuario.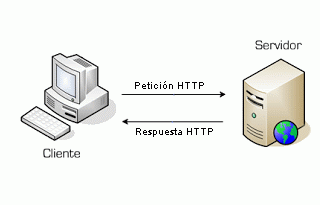
Para que este protocolo funcione correctamente necesita de un mecanismo que permita identificar los recursos, con el fin de que el cliente los pueda llamar de la forma correcta, y el servidor sepa en todo momento y de manera unívoca qué es lo que se busca. Ese mecanismo es la URL (Uniform Resource Locator). Es una forma estándar de hacer referencia a cualquier recurso (servicio) de Internet (sí, porque no sólo vale para el servicio HTTP).
Si el servidor HTTP no puede mostrar el recurso solicitado, envía un código de respuesta formado por tres dígitos. El primero indica el estado, mientras que los otros dos explican la naturaleza exacta del error. En otras palabras, es el origen del famoso Error 404: URL not found.
Los códigos de respuesta
Esta tabla aglutina lo que representa cada uno de los códigos que envía el servidor al cliente informando de su estado:
| Código | Mensaje | Descripción |
| 1xx | Mensaje de información | Estos códigos no se utilizan en la versión 1.0 del protocolo |
| 2xx | Éxito | Estos códigos indican la correcta ejecución de la transacción |
| 200 | OK | La solicitud se llevó a cabo de manera correcta |
| 201 | CREATED | Sigue a un comando POST e indica el éxito, la parte restante del cuerpo indica la dirección URL donde se ubicará el documento creado recientemente. |
| 202 | ACCEPTED | La solicitud ha sido aceptada, pero el procedimiento que sigue no se ha llevado a cabo |
| 203 | PARTIAL INFORMATION | Cuando se recibe este código en respuesta a un comando de GET indica que la respuesta no está completa. |
| 204 | NO RESPONSE | El servidor ha recibido la solicitud, pero no hay información de respuesta |
| 205 | RESET CONTENT | El servidor le indica al navegador que borre el contenido en los campos de un formulario |
| 206 | PARTIAL CONTENT | Es una respuesta a una solicitud que consiste en el encabezado range. El servidor debe indicar el encabezadocontent-Range |
| 3xx | Redirección | Estos códigos indican que el recurso ya no se encuentra en la ubicación especificada |
| 301 | MOVED | Los datos solicitados han sido transferidos a una nueva dirección |
| 302 | FOUND | Los datos solicitados se encuentran en una nueva dirección URL, pero, no obstante, pueden haber sido trasladados |
| 303 | METHOD | Significa que el cliente debe intentarlo con una nueva dirección; es preferible que intente con otro método en vez de GET |
| 304 | NOT MODIFIED | Si el cliente llevó a cabo un comando GET condicional (con la solicitud relativa a si el documento ha sido modificado desde la última vez) y el documento no ha sido modificado, este código se envía como respuesta. |
| 4xx | Error debido al cliente | Estos códigos indican que la solicitud es incorrecta |
| 400 | BAD REQUEST | La sintaxis de la solicitud se encuentra formulada de manera errónea o es imposible de responder |
| 401 | UNAUTHORIZED | Los parámetros del mensaje aportan las especificaciones de formularios de autorización que se admiten. El cliente debe reformular la solicitud con los datos de autorización correctos |
| 402 | PAYMENT REQUIRED | El cliente debe reformular la solicitud con los datos de pago correctos |
| 403 | FORBIDDEN | El acceso al recurso simplemente se deniega |
| 404 | NOT FOUND | El servidor no halló nada en la dirección especificada. Se ha abandonado sin dejar una dirección para redireccionar… |
| 5xx | Error debido al servidor | Estos códigos indican que existe un error interno en el servidor |
| 500 | INTERNAL ERROR | El servidor encontró una condición inesperada que le impide seguir con la solicitud (una de esas cosas que les suceden a los servidores…) |
| 501 | NOT IMPLEMENTED | El servidor no admite el servicio solicitado (no puede saberlo todo…) |
| 502 | BAD GATEWAY | El servidor que actúa como una puerta de enlace o proxy ha recibido una respuesta no válida del servidor al que intenta acceder |
| 503 | SERVICE UNAVAILABLE | El servidor no puede responder en ese momento debido a que se encuentra congestionado (todas las líneas de comunicación se encuentran congestionadas, intentelo de nuevo más adelante) |
| 504 | GATEWAY TIMEOUT | La respuesta del servidor ha llevado demasiado tiempo en relación al tiempo de espera que la puerta de enlace podía admitir (excedió el tiempo asignado…) |
¿Y qué hago con esos códigos?
Desde el punto de vista de la arquitectura de la información web estos códigos arrojan una información muy valiosa que no deberíamos desdeñar. Se puede acceder a ellos a través del fichero log del servidor HTTP, y nos aporta datos muy importantes sobre el estado y diagnóstico del sitio web. Gracias a ellos podemos acceder de manera más sencilla a resolver errores graves del servicio, de posicionamiento, de estructuración de la información, etc.
- Códigos 2xx: en condiciones normales deberíamos prestar atención a qué ficheros importantes del servidor HTTP devuelven el código 200 (especialmente robots.txt y sitemap.xml). Los errores 204 se suelen producir cuando uno de los frames de un sitio web contiene una página en blanco, por lo que se puede solucionar poniendo algún texto oculto (palabras con el mismo color que el fondo de la página). Los errores 206 se producen cuando, por ejemplo, el cliente no recibe datos embebidos en un fichero binario, por ejemplo, cuando no se carga completamente un fichero PDF. Eso se soluciona reduciendo el tamaño del PDF, o ampliando el ancho de banda contratado en el hosting
- Códigos 3xx: desde el punto de vista del posicionamiento web son los que más penalizan. Por ejemplo, el 301 se usará cuando se mueva un contenido determinado, que ya haya sido indizado por el motor de búsqueda. Para corregirlo bastarán con realizar un redireccionamiento permanente, comunicándole de esta forma al robot que una o varias páginas han sido movidas a una nueva ubicación de forma definitiva, así el motor de búsqueda indizará la nueva página, en vez de la redirigida. Con el 302 se indica que, de manera temporal, el contenido referenciado se ha movido, con lo que el motor de búsqueda seguirá indizando la página original y no dará de baja ese registro en la base de datos, provocando la pérdida del posicionamiento conseguido. Si, por ejemplo, se cuenta con un ancho de banda muy limitado en el hosting, se puede usar el 304 para indicar que ese recurso no ha cambiado desde la última solicitud y que, por lo tanto, no es necesario volver a rastrearlo.
- Códigos 4xx: lo ideal es que si alguien introduce un URL en el navegador, a continuación aparezca la información que desea. Si por el contrario aparece un error 4xx habrá una penalización grave desde todos los puntos de vista. Ya no solo se perderá posicionamiento, sino que si el hecho persiste se perderán usuarios, visibilidad, se dejarán de prestar servicios… en definitiva, nos autodescartamos del mercado. Por eso siempre viene bien contar con un gestor de enlaces rotos, que se encargue de automatizar el proceso de analizar, cada x tiempo, si existe este tipo de problemas. Si el error se produce por un servicio o recurso que está temporalmente inactivo, lo mejor es hacer una redirección 301, con lo que se minimizarán las pérdidas.
- Códigos 5xx: avisan de que hay algo en el servidor no está funcionando de manera correcta. Puede ser desde un servicio a un error interno.
Así que ya sabes, en la web nada sale por accidente. Si aparece uno de estos errores hay que tomar medidas.
Deja una respuesta